Everything You Need to Know About Data Labeling: 2023 Edition
 By Anolytics | 08 June, 2023 in Data Annotation | 8 mins read
By Anolytics | 08 June, 2023 in Data Annotation | 8 mins read
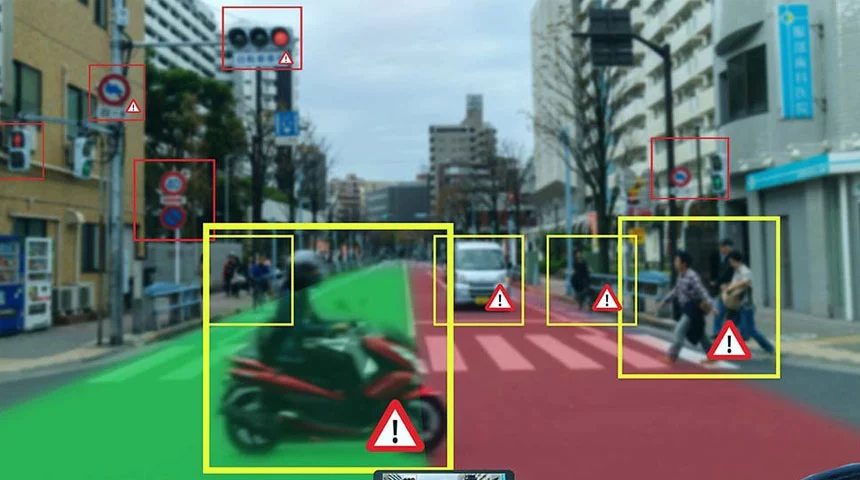
Data Labeling: What is it?
An image, video, text, or audio can be labeled with tags or labels. A machine learning model learns to identify these particular classes of objects by using these tags to identify the objects in the data.
Machine Learning Training Data: What is it?
Machine learning models learn about data when they are fed training data. A machine learning model will need to use a variety of training data types, including images, audio, text, or features, based on the task at hand. You can annotate or unannotate it. The corresponding label is called “ground truth” when training data is annotated.
Unlabeled vs. labeled data: pros and cons
Machine learning tasks require different training datasets. Three types of data are required for machine/deep learning algorithms.
Supervised learning
An annotated set of data and corresponding labels are needed for supervised learning, the most common type of machine learning. In this paradigm, image segmentation and classification are popular tasks.
In most training procedures, annotated data is fed to the machine for learning, and unannotated data is used to test the learned model.
In the testing stage, hidden labels are typically added to annotated data to check the accuracy of the algorithm. In supervised machine learning, annotated data is absolutely essential.
Unsupervised learning
Without knowledge of the labels on the input data, unsupervised learning uses unannotated input data to train models.
Autoencoders have the same output as the input, which is a common unsupervised training algorithm. The data is grouped into ‘n’ clusters using unsupervised learning algorithms. Semi-supervised learning methods use supervised methods.
The model is trained using both annotated and unannotated data in semi-supervised learning.
By combining both types of data one can reduce the cost of data annotation, but the training data is usually based on many severe assumptions. Classification of protein sequences and Internet content are examples of semi-supervised learning.
HITL (Human in the Loop): what is it?
An AI model’s results are constantly supervised and validated by a human, known as Human-In-The-Loop.
There are 2 key ways in which humans become part of the ML Process :
Labeling training data: For machine learning models to work, training data must be labeled by human annotators.
Training the model: Scientists train models by monitoring losses and predictions constantly. In some cases, a human validates model performance and predictions.
Data labeling approaches
It is possible to label in various ways. The project duration, number of people involved, and problem statement determine how long the process will take.
There are many different forms of labeling and annotation that can be done by internal labeling and crowdsourcing, but the terminology can also encompass AI and active learning.
Annotating data is commonly done in the following ways.
In-house data labeling
Data scientists and data engineers employed by the organization are generally responsible for doing in-house data labeling to ensure the highest level of quality.
For industries like insurance and healthcare, high-quality labeling is crucial, and it often requires consultation with professionals in the respective fields to ensure that data is adequately labelled.
This is to be expected for in-house labeling since as annotation quality increases, the overall labeling and cleaning process takes longer, resulting in a very slow workflow.
Crowdsourcing
Using crowdsourcing, annotated data is obtained by using the services of numerous freelancers registered with crowdsourcing platforms.
Most of the datasets that have been annotated contain trivial data, such as images of animals, plants, and the natural environment, and they do not require any additional expertise. Thus, tens of thousands of data annotators are often registered on platforms for crowdsourcing the annotation of simple datasets.
Outsourcing
An organization or individual is hired to perform the task of data annotations, a middle ground between crowdsourcing and in-house data labeling.
When outsourcing to individuals, it is possible to assess their knowledge on the subject matter before the work is performed.
Annotation datasets can be assembled in this manner for projects without a large amount of funding, yet requiring a significant level of data annotation.
Machine-based annotation
In recent years, machine-based annotation has become one of the most popular forms of annotation. Data annotation using machine-based tools and automation can dramatically increase the speed of data annotation without compromising its quality.
Fortunately, recent advances in traditional machine annotation tools have significantly reduced the workload on human labelers by using unsupervised and semisupervised machine learning algorithms.
In the context of AI data labeling, semi-supervised algorithms, such as active learning, as well as unsupervised algorithms like clustering may reduce annotation times by a great deal.
Data labeling types that are commonly used
A machine-learning algorithm performs the task we define for our data through data labeling.
For example—
We feed a machine learning algorithm data such as images of rust and cracks if we wish to develop a defect inspection algorithm. A polygon would be used to indicate the location of cracks or corrosion, and tags would be used to indicate their name.
Here are some common AI domains and their respective data annotation types.
Computer Vision
Annotated visual data, such as images, is required in the study of computer vision (the research aimed at helping computers understand the world around them). There are several types of annotations that can be applied to data in computer vision, depending on what the model is supposed to do visually.
Common data annotation types based on the task are listed below.
Image Classification:
In order to classify images, data annotation requires the addition of tags to the images. Approximately how many classes the model is capable of classifying is determined by the number of unique tags in the entire database.
Classification problems can be further divided into:
Binary class classification (which consists of only two tags)
Multiclass classification (which contains multiple tags)
In addition, multi-label classifications can also be observed, particularly in the case of disease detection, where multiple tags are associated with each image.
Image Segmentation:
Image segmentation is the process of separating objects from their backgrounds and other objects in the same image with the aid of a Computer Vision algorithm. The term “pixel map” refers to a map with the same dimensions as the image containing 1 where the object is present and 0 where no annotation has yet been added.
Object Detection:
By using computer vision, objects are detected and their locations are identified.
It is important to note that the annotation of data in object detection differs significantly from that in image classification, in which bounding boxes are used to identify each object. Objects in an image are contained within bounding boxes, which represent the smallest rectangular regions. There is usually a label associated with each bounding box in the image when bounding box annotations are made.
Typically, the image number/image ID serves as a key within a separate JSON file containing this information and associated tags.
Pose estimation:
Using computer vision tools, pose estimation can be used to estimate a person’s pose in an image. The process of estimating pose involves detecting key body points and correlating them to determine the pose. Thus, key points from an image would serve as the ground truth for the pose estimation model. Using tags, our coordinate data would be labeled to identify a particular key point in the image, with each coordinate giving the location.
Natural Language Processing
NLP describes how human languages are analyzed and represented both between humans and machines. The field of computational linguistics has developed further with Artificial Intelligence and Deep Learning.
Here are some of the data labeling approaches for labeling NLP data.
Entity annotation and linking:
A data corpus that has not been labelled can be annotated with entities or particular features.
According to the task at hand, the word ‘Entity’ may take a variety of forms.
We have named entity annotations for annotating proper nouns. This procedure refers to identifying and tagging names in a text. The process of keyphrase tagging is used to analyze phrases by annotating keywords or keyphrases from the text. POS tagging, also known as Parts of Speech tagging, is a method used for annotating and analyzing functional elements of texts, such as verbs, nouns, and prepositions.
Language-generating techniques use POS tags.
Entity annotation follows entity linking, which assigns a unique identity to each of the annotated entities by linking them to the data repositories. Particularly when ambiguous data is present in the text, disambiguation is necessary.
When entities are linked, semantic annotations are added to their semantic information.
Text classification:
We assign one or more labels to blocks of text, in a similar fashion to the classification of image data.
A text classification is different from entity annotation and linking, since it considers the text as a whole and assigns a number of tags to it. There are a variety of methods for classifying text, including sentiment analysis (for text classification based on sentiment) and topic categorization (for text categorization based on topic).
Phonetic annotation:
Annotating commas and semicolons based on their placement in a text is known as phonetic annotation. It is particularly important in chatbots that generate text based on input. An unintended comma or stop can alter the structure of a sentence.
Audio annotation
In order to properly utilize audio data, audio annotation is necessary, such as speaker identification and extracting linguistic tags from audio samples. As opposed to speaker identification, which involves simply tagging or labeling an audio file, annotation of linguistic data entails a more involved process.
The first step in annotating linguistic data is to identify the linguistic region, since an audio recording will never contain 100% speech. A transcript of the speech is generated by using Natural Language Processing (NLP) algorithms.
How does data labeling work?
The data labeling process follows the following chronological sequence:
Data collection:
In order to train the model, raw data is collected. In order to feed this data directly into the model, this data is cleaned and processed in order to form a database.
Tagging of data:
In order to tag the data and associate it with meaningful context, various approaches are used to label the data and provide the machine with ground truth information.The data labeling process follows the following chronological sequence:
Quality assurance:
When it comes to bounding box and keypoint annotations, the quality of the annotation is often determined by the preciseness of the tags for each data point. These annotations can be evaluated using quality assurance algorithms such as the consensus algorithm and the Cronbach’s alpha test
Analyzing data with Anolytics
We can perform accurate annotations for segmentation, classification, object detection, or pose estimation using analytics, as it provides us with a vast array of tools that are indispensable for data annotation and tagging.
Best practices for data labeling
Almost every workplace that talks about artificial intelligence uses supervised learning, one of the most common forms of machine learning today.
For you to avoid your model crumbling due to poor data, here are some best practices for data labeling for AI:
Proper dataset collection and cleaning:
We should pay particular attention to the data when discussing machine learning. The data should be diverse, but extremely relevant to the problem statement. The diversity of data provides us with the opportunity to infer ML models in a variety of real-world scenarios and maintain specificity to reduce the chance of error. It is equally important to ensure that the model is not overfitted to one particular scenario by conducting appropriate bias checks.
Proper annotation approach:
For data labeling, the assignment of labeling tasks is the next most important step. Whether the data will be annotated in-house or outsourced, crowdsourcing will have to be used to label the data. In order to maintain a budget without compromising the accuracy of annotations, it is crucial to choose the right approach to data labeling.
QA checks:
In the case of crowdsourcing or outsourcing labeled data, quality assurance checks are an absolute necessity. Data that is labeled incorrectly or with false labels may not be fed into ML algorithms as a result of QA checks. As a result of improper and imprecise annotations, an otherwise dependable machine learning model can easily become invalidated by noise.
Data labeling: TL;DR
In our discussion of data annotation, we discussed the various forms of data annotation, some common approaches to data annotation, and some best practices.
Final Thoughts
In general, it is assumed that AI algorithms operate on accurate ground truth data. Human annotation of data results in inaccurate predictions, which reduces the overall accuracy of these models.
A major challenge facing AI today is labeling and annotating data, which poses a barrier to integrating AI on a large scale in various industries. In order for any project to succeed, data annotation is an essential component that can enhance the performance of a machine learning model.
please contact our expert.
Talk to an Expert →
You might be interested

- Data Annotation 02 Aug, 2019
Five Reasons to Outsource Your Data Annotation Project
Artificial Intelligence (AI) and Machine Learning (ML) development is mainly rely on training data sets, that helps the
Read More →
- Data Annotation 17 Dec, 2019
Why Data Annotation is Important for Machine Learning and AI?
Data annotation is the process of making the contents available in various formats like text, videos and images, recogni
Read More →
- Data Annotation 13 Oct, 2020
Top Most Data Labeling Challenges in Annotation Companies
Data labeling is not a task, it requires lots of skills, knowledge and lots of effort to label the data for machine lear
Read More →