Data Annotation Guide
 By Anolytics | 02 December, 2022 in Data Annotation | 9 mins read
By Anolytics | 02 December, 2022 in Data Annotation | 9 mins read
Since the advent of artificial intelligence (AI), it has become an integral part of real-life systems. There is hardly an industry or space unaffected by AI or businesses that have not benefited from AI in some way. It’s incredible how machines can learn and act the same way as humans.
While artificial intelligence has a long history, it appears that industries are just beginning to discover its benefits. In contrast, AI and machine learning are applicable to virtually every industry today.
Even though business owners seek AI and machine learning for a variety of reasons, they rarely understand the whole process and its essential steps. The majority of businesses whose core goals are not related to data science are willing to adopt an AI mindset in order to gain an advantage over their competitors.
AI implementation in a manufacturing process requires an expert-level understanding of data collection, categorization, filtering, labeling, and annotation techniques.
What are the steps involved? When planning an AI project, what are the most important things to consider? Is there an easy way to locate the right people? Are there any experts you can partner with for parts of the project?
Data annotations and data labeling tools: what are they exactly?
It’s time to put your worries behind you. For your understanding of what data annotation is, why it is needed, and how it is done, we’ve put together a comprehensive guide. We’ll dive right in, shall we?
What Data Annotation Is & Why It Matters
Assume you have started planning your AI project. A detailed plan of the major steps has been mapped out (from collecting data to designing algorithms to implementing the algorithms into the business platforms). A team of engineers builds your algorithm, and a team of data scientists collects, analyzes, and processes the data. All resources have been allocated, and even a data scientist has been hired. Isn’t it also necessary to annotate data?
Unless you properly train your algorithm, you won’t get great results. Data can be fed into the system, unlabeled as it is, and you might even get a few advantages. The capabilities of a machine learning algorithm, however, will be quite limited.
Due to the fact that machines think differently from humans, this is to be expected. The human mind is naturally able to comprehend interdependent relationships and recognize the differences between data sets.
In order for a machine to recognize these differences and make connections, it must be taught how to see them. Training is required to train it to think like a human. Labels are needed here.
To ensure that your training data is of the highest quality, you should use data labeling services by a company with industry expertise.
How Does Data Labeling Differ From Annotation?
How does labeling work? Earlier, we discussed annotations, and now there’s another concept to grasp.
No worries! These terms aren’t really different in reality. In machine learning, data annotation and data labeling refer to the same thing: the process of adding meaningful labels to particular data sets to explain what they contain.
Annotation tasks describe to a machine how different types of data are interpreted. The tasks we specialize in at Anolytics include semantic segmentation, 2D boxes, and optical character recognition (NLP).
But let’s begin by looking at how data annotations help an ML algorithm think like a human.
Annotating Data for AI: What is the Process?
Collecting your data is obviously the first step towards working with it. Depending on your needs, the format of your data will differ. If you plan to build an image recognition system, you will need to collect several thousand pictures of objects that your system will need to recognize. You need an OCR algorithm that can read tens of thousands of pages of text in order to automate the conversion of handwritten text into text files that you can share and edit.
The question is: how much data do you need? No one really knows.
More data is better, according to the general consensus. A vast amount of data is used to generate hidden patterns using artificial intelligence, which is called big data. An online retail store offering flexible and always-updating recommendations would be a good example. An AI-based system uses these predictions to suggest items to users with similar backgrounds, genders, and ages, based on what items they prefer to buy together.
Overfitting (or overtraining) may occur with your model. Since getting decent data is a time-consuming and costly process in modern times, you won’t have a major issue with it. Instead of overthinking how much you need, consider what standard you need when it comes to data.
What matters more is collecting the best data to train machine learning algorithms to finally incorporate artificial intelligence into applications, devices, or assembly lines.
In-Demand Labeling Experts vs. Companies that Provide Data Annotation
You must make a decision once you’ve collected and cleaned your data and ensured it’s ready for labeling. It is a tedious and time-consuming process to annotate data.
The data processing and annotation process alone accounts for almost 80% of all work associated with an AI project. Since the data isn’t ready yet, developers will have to wait until they have the data before they can train the algorithm and use it.
As a result, many businesses opt to outsource annotations as part of their AI projects. While the data is being annotated, this allows the core processes to be focused on. Saving time, money, and expert effort is one of the benefits of outsourcing the annotation & labeling part to an expert around.
We’ve put together a quick guide to help you gain a better understanding of data annotation and labeling processing.
A review of the major steps in the labeling process in two fields of AI (computer vision and natural language processing) is included in this guide, as well as an analysis of the advantages and disadvantages associated with human annotation.
Types of Data Annotation: CV & NLP
We’ve discussed data annotation fields and types before, but what exactly are they? It’s important to understand that different types of data have to be handled differently. A photograph with a label cannot be treated the same as text (even if it is a photo of the text).
Two fields of artificial intelligence can cover most data annotation tasks:
- Computer Vision
Computer vision deals with images, photos, and videos as visual formats of data. There are many different tasks you can perform within the computer vision field, such as the recognition of facial expressions, detection of movement, and autonomous driving. - Language Recognition
This field focuses on image-based recognition of text, with the exception of textual data. It aims to teach machines how to understand language by teaching them how to understand human speech.
A few different data types can also be used to annotate freestanding data. In LiDAR, lasers are used, while in RADAR, waves are used to measure distance. Afterward, an algorithm “sees” the surrounding environment by using a 3D cloud of data points.
In both CV and NLP, data annotation occurs in several forms.
Types of data annotations in computer vision
Computer vision is one of the most debated topics in the current AI landscape. On your phone (something like facial recognition or automated classification of images), in manufacturing settings (emotion recognition for remote education), and in public settings (emotion recognition for remote education).
In order to understand why computer vision algorithms are so popular, let’s look at the types of annotation tasks that enable them to do so.
- Image Categorization
In machine learning, this type of task is also known as image classification. By categorizing images, ML algorithms can be trained to group them into predefined categories. These classes will make it possible for a machine-learning model to identify what is detected in a photo after training.
It can, for instance, recognize the difference between a Georgian and a rococo armchair if it is trained to recognize different furniture styles. - Semantic Segmentation
An image can be viewed as a separate entity by a human. Using semantic segmentation, a machine can be trained to associate each pixel of an image with a class of objects (e.g., trees, vehicles, humans, buildings, highways, and sky). Once that’s done, the machine learning model clusters similar pixels together.
The machine then trains to “see” the separate objects on the picture using the map created by clustering different object classes. - 2D boxes
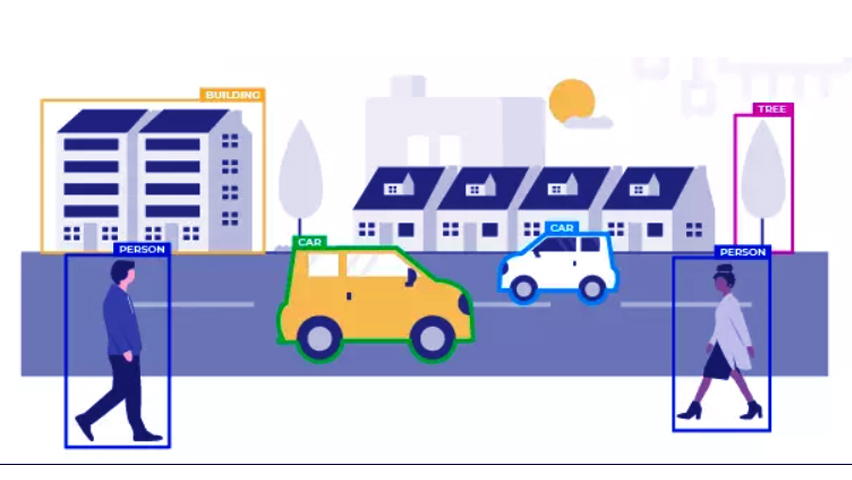
Data annotations of this type also go by the name bounding boxes. These annotations illustrate objects in 2D by drawing boxes around them on an image. For example, cars, people, household objects, cars are used in autonomous driving algorithms, etc.
Using similar parameters, the machine then classes objects into predefined categories (cars, people, household items, etc.). - 3D Cuboids
The initial frame around an object can be enhanced with 3D cuboids similar to 2D boxes. A two-dimensional image can be given an in-depth perspective with this type of data annotation.
An image with the third dimension also shows rotation, relative position, and predictions of movement in addition to size and position in space. - Polygonal Annotation
As frames cannot capture the shape of an object quickly, they are not sufficient for training an ML algorithm. For objects with complicated outlines (such as curvy or multi-sided), polygonal annotation can be used.
Objects and their positions in space can be recognized by machines based on their polygonal shapes. Therefore, you can explain what a lamp or vase is or what type of object they are to your model in the interior design project. - Keypoint Annotation
There is a type of annotation that aims directly at this, despite artificial objects being simpler to explain to algorithms than natural objects. In keypoint annotations, the main (key) points of a natural object are defined so that a machine learning algorithm can predict the shape and movement of the object.
People and animals use keypoint annotations for a variety of purposes, including facial and emotion recognition, tracking their movements (such as in sports apps or exercise programs), etc. The versatility of this type of annotation allows it to also be used to track machine-made objects’ positions.
In video labeling, object tracking is a common type of annotation. Video annotations are somewhat similar to image annotations, but they take a greater amount of work.
To begin with, a video needs to be broken up into separate frames. Thereafter, each frame is considered a separate image. It is vital for the algorithm to detect objects because it enables it to establish links between frames, informing it of the objects in different frames that appear in different positions. A moving object is separated from a static background by contrasting it in every frame with the moving object.
Data Annotation Types in NLP
Computer vision has been the buzz for a while, but natural language processing has many applications the general public does not know about. Data annotations based on natural language processing are ubiquitous in our daily lives. In addition to voice recognition, QR codes can be scanned with a camera, and customer profiles can be populated by a CRM system after a single phone call.
1. Text Classification
There is no doubt that text classification is one of the most challenging NLP tasks since it allows us to group texts according to their content. Key phrases and words are used as tags to explain what ML algorithms need to look for when classifying a text.
Text classification can be used, for example, in an email: certain messages are automatically classified as “spam”, “promotions”, or “updates” based on the cues inside them.
2. Optical Character Recognition (OCR)
Today, businesses still thrive on paper. Electronic workflows, however, are becoming more and more popular as people realize the value they bring. This is a perfect example of how OCR data annotation is useful for switching between the two tasks. Images of text can be converted into machine-readable text (both typed and handwritten, for example).
A lot of other AI projects use OCR as well, not just in business. Typical CV cameras on the road scan license plates using this technology. By using OCR, you can translate phrases written in other languages. Read our blog for a comprehensive guide to OCR to learn more about the possibilities.
3. Named Entity Recognition (NER)
An automated process called Named Entity Recognition (NER) is based on identifying and categorizing words, phrases, and entities within a text. Any information you want to include in your order, such as names, places, and prices.
You might think it’s too simple at first glance, but imagine dealing with a large amount of text. With NER data annotation, a machine can find specific information faster than you can on your own. As a result of NER, you can focus on your most important tasks and automate this task.
4. Intent/Sentiment Analysis
The data annotation, in this case, combines two types. To begin with, sentiment analysis involves analyzing a text and categorizing it according to its tone. A typical example is deciding whether to use a friendly, neutral, or negative tone (although other possibilities include angry or friendly tones). Customer satisfaction research, public opinion monitoring, and brand reputation management are all common applications of this type of data annotation.
A text’s intention can be analyzed by using the Intent Analysis section of this data annotation task. Likewise, these can range from making a purchase to seeking assistance to submitting a complaint. By automating this task, customer reviews can be collected more efficiently. For complex systems (e.g. CRM systems), it is also possible to build a hierarchy of priority.
So what exactly does data annotation mean?
In order to build and train a high-performing and flexible ML algorithm, is an important step. The algorithm can be skipped when it is only required to perform a limited function. Annotating data has become more important when there is big data and high competition because it enables machines to learn how to see, hear, and write as we do.
Final Thought
The annotation of data can, despite its benefits, be time-consuming and labor-intensive. Most businesses look for data annotation partners rather than doing it themselves because it takes a lot of time and manual labor.
Anolytics, with nearly a decade-long data exposure across diverse industries, can be your outsourced partner in sufficing your data requirements for your AI and machine learning project. Working with us will save you time, effort, and all the hassles that might arise along the course.
Did you get to do data things for your AI initiatives? Anolytics could be all the support for your AI training data needs. Get in touch to get started.
please contact our expert.
Talk to an Expert →
You might be interested

- Data Annotation 02 Aug, 2019
Five Reasons to Outsource Your Data Annotation Project
Artificial Intelligence (AI) and Machine Learning (ML) development is mainly rely on training data sets, that helps the
Read More →
- Data Annotation 17 Dec, 2019
Why Data Annotation is Important for Machine Learning and AI?
Data annotation is the process of making the contents available in various formats like text, videos and images, recogni
Read More →
- Data Annotation 13 Oct, 2020
Top Most Data Labeling Challenges in Annotation Companies
Data labeling is not a task, it requires lots of skills, knowledge and lots of effort to label the data for machine lear
Read More →