Scenario identification is the result of 3D point cloud segmentation
 By Anolytics | 14 December, 2021 in 3D Point Cloud | 3 mins read
By Anolytics | 14 December, 2021 in 3D Point Cloud | 3 mins read
Data can take many different forms. Images are widely used in the processing of visual information. Images are made up of a two-dimensional grid of pixels that depict our three-dimensional reality.
Problems involving pictures have led to some of the most effective developments in machine learning. However, having a three-dimensional array of pixels representing a whole volume is less typical when directly recording data in 3D.
A point cloud is one of the easiest and most cost-effective ways to obtain spatial data in 3D. Surprisingly, there hasn’t been much work done on machine learning for point clouds, and most people are unaware of the notion.
Machine Learning and Point Clouds
Classification and segmentation are the two most prevalent sorts of issues encountered while performing machine learning on point clouds.
In classification, the aim is to assign a single label to the complete point cloud. There can be two labels (for example, is this data on a cat or a dog?) or several labels (for example, is this data about a vehicle, plane, boat, or bike?)
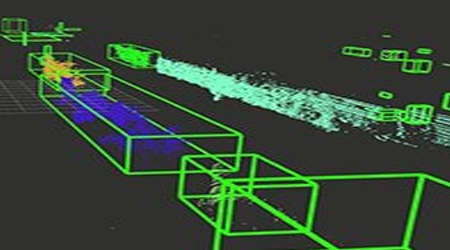
In segmentation, if we might wish to isolate the wheels, handlebars, and seat from a point cloud depicting a bike then segmentation is used.
Complex point clouds that depict a complete environment rather than a single item are likewise handled via segmentation. We may have a point cloud depicting a traffic crossroads and wish to differentiate each individual car, person, and lights, for example (Semantic Segmentation).
What is 3d point cloud segmentation and Related Problems?
The technique of segmenting 3D point clouds into several homogenous regions is known as 3D point cloud segmentation. Points in the same region will have the same attributes. Because of the significant redundancy, uneven sample density, and lack of apparent organization in point cloud data, 3D segmentation is a difficult process.
A crucial stage in the processing of 3D point clouds is segmenting them into foreground and background. In 3D data, the form, size, and other features of objects can be precisely determined. Segmenting objects in 3D point clouds, on the other hand, is a difficult process.
The data in a point cloud is typically noisy, sparse, and disorganized. Aside from that, the point sampling density is uneven, and the surface form might be arbitrary due to the lack of a statistical distribution pattern in the data. Furthermore, the backdrop gets entangled with the foreground owing to limitations in 3D sensors.
Furthermore, creating a deep learning model that is computationally efficient and has a small memory footprint to conduct segmentation is tough. The segmentation method is useful for studying a scene in a variety of applications, including object detection and recognition, classification, and featur extraction.
Also Read: How Semantic Segmentation & Landmark Annotation Improves Facial Recognition?
3D Point Cloud Segmentation For Scene Interpretation
Semantic segmentation of 3D point clouds is becoming increasingly important in the realm of 3D scene interpretation. Indoor scene knowledge has benefited from point cloud analysis, and it has lately become an important component of outdoor applications. This is because 3D sensors like LiDAR and the Matterport scanner are becoming more widely available and affordable.
Convolutional neural networks dominate the 2D picture domain for many applications (including semantic segmentation). 2D convolutions take advantage of the convolutional operator’s locality to handle big datasets with high-resolution pictures. They enable deeper and more complex models while remaining efficient by reducing the number of model parameters.
However, unlike pixel neighbourhoods, point clouds have no fundamental order.
In 3D space, they are often sparse, and the density changes depending on the distance to the sensor. In addition, the number of points in a cloud can easily outnumber the number of pixels in a high-resolution image by many orders of magnitude. Because of these characteristics, standard convolutional neural networks struggle to handle point clouds directly.
There have been various classical methodologies used to the challenge of semantically labelling 3D point clouds before the introduction of deep learning technologies. Since then, deep learning methods have been divided into two groups: methods that impose structure on the unstructured 3D point cloud (via voxelization or projection) and then use standard convolutions, and methods that operate directly on the 3D point clouds.
Also Read: How To Label Data For Semantic Segmentation Deep Learning Models?
3D Point Cloud Annotation Services
The computer vision training data you need to train your machine learning or deep learning model is better quality data. Anolytics.ai is right here, annotating all forms of data, including LiDAR, with a staff of devoted and highly competent annotators.
Our annotation services will provide an edge in obtaining high-quality training data for self-driving vehicles, robotics, and drones when it comes to 3D point cloud annotation.
Conclusion
Over the last few years, a lot of effort has gone into segmenting 3D point cloud data. To successfully segment point clouds in real time, many approaches have been devised.
However, it is obvious that effective real-time application is still a work in progress due to several constraints posed by point cloud data.
please contact our expert.
Talk to an Expert →
You might be interested

- 3D Point Cloud 18 Jan, 2021
What is the Best Challenges with Annotate 3D Point Cloud Data for LIDARs?
3D point cloud data is one of the most complex types of machine learning data used to generate the most useful training
Read More →